What are evaluations?
If you are using LLMs to build applications, it is important to evaluate the performance of your models. Evaluations help you understand how well your models are performing and identify areas for improvement. For example: If you are using GPT-3.5-Turbo to build a chatbot, and you want to switch to a different model, you can run evaluations to compare the performance of the two models and choose the one that works best for your application.How to run evaluations
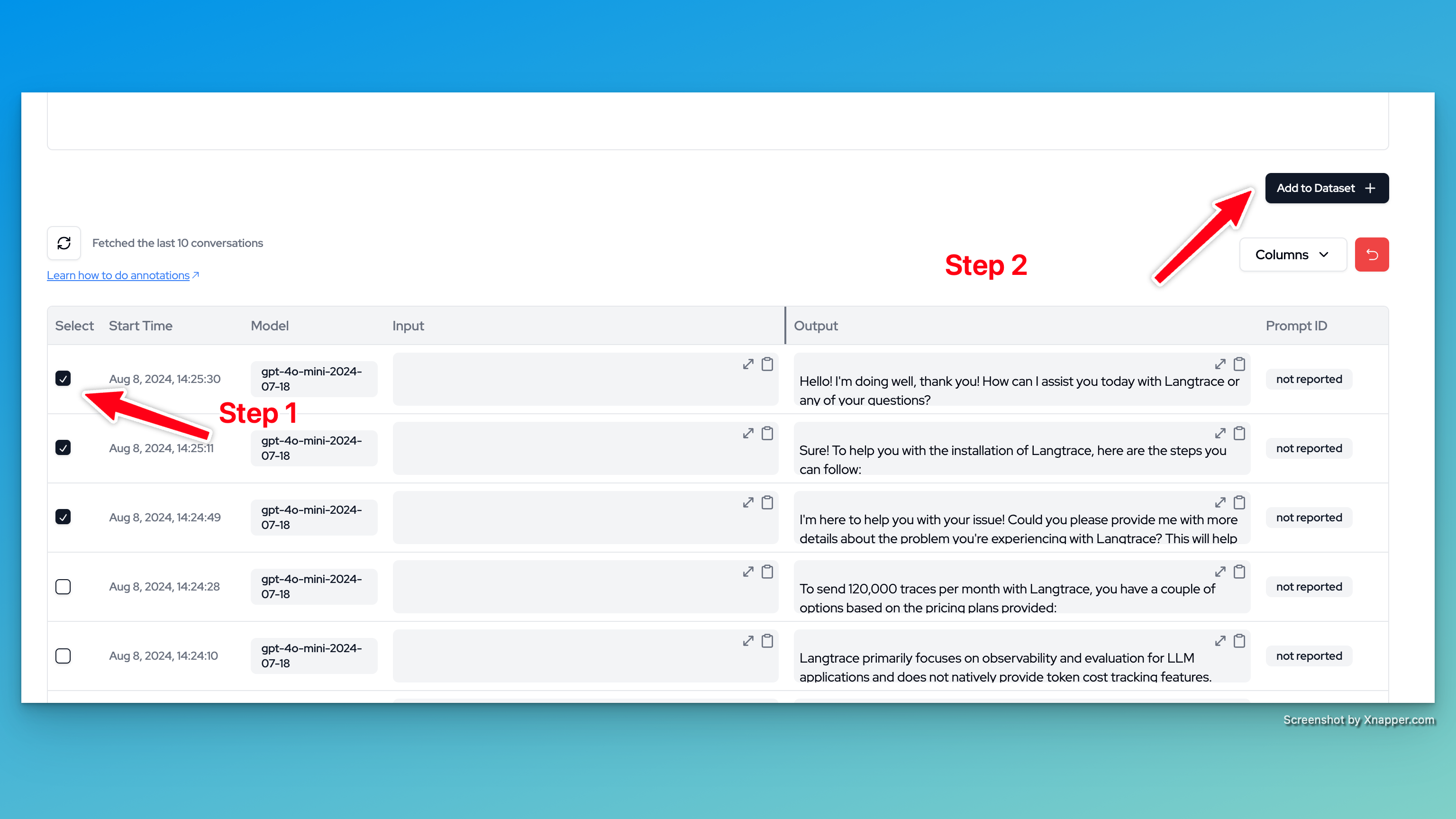
Langtrace relies on Inspect AI, an Open Source framework for large language model evaluations created by the UK AI Safety Institute. You can run evaluations on annotated datasets as well as your own datasets. Inspect provides many built-in components, including facilities for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Extensions to Inspect (e.g. to support new elicitation and scoring techniques) can be provided by other Python packages. In order to run evaluations, you need to have a dataset that has been annotated or curated with Langtrace. To annotate a dataset, you can follow the steps in the Annotate & Measure guide. Once you have an annotated dataset, follow the steps below to run evaluations.- Setup a project on Langtrace, trace a bunch of LLM completions and create a dataset out of the traced completions.
- Create an independent python project and install Inspect AI
- Add the LANGTRACE_API_KEY to your environment variables as shown below. Note: If you don’t have an API key, you can generate one by following the steps in the Generate API Key guide.
If you are self-hosting, set the LANGTRACE_API_HOST environment variable to the URL of your Langtrace instance.
- Copy the dataset ID from Langtrace and replace
<datasetId>in the script below
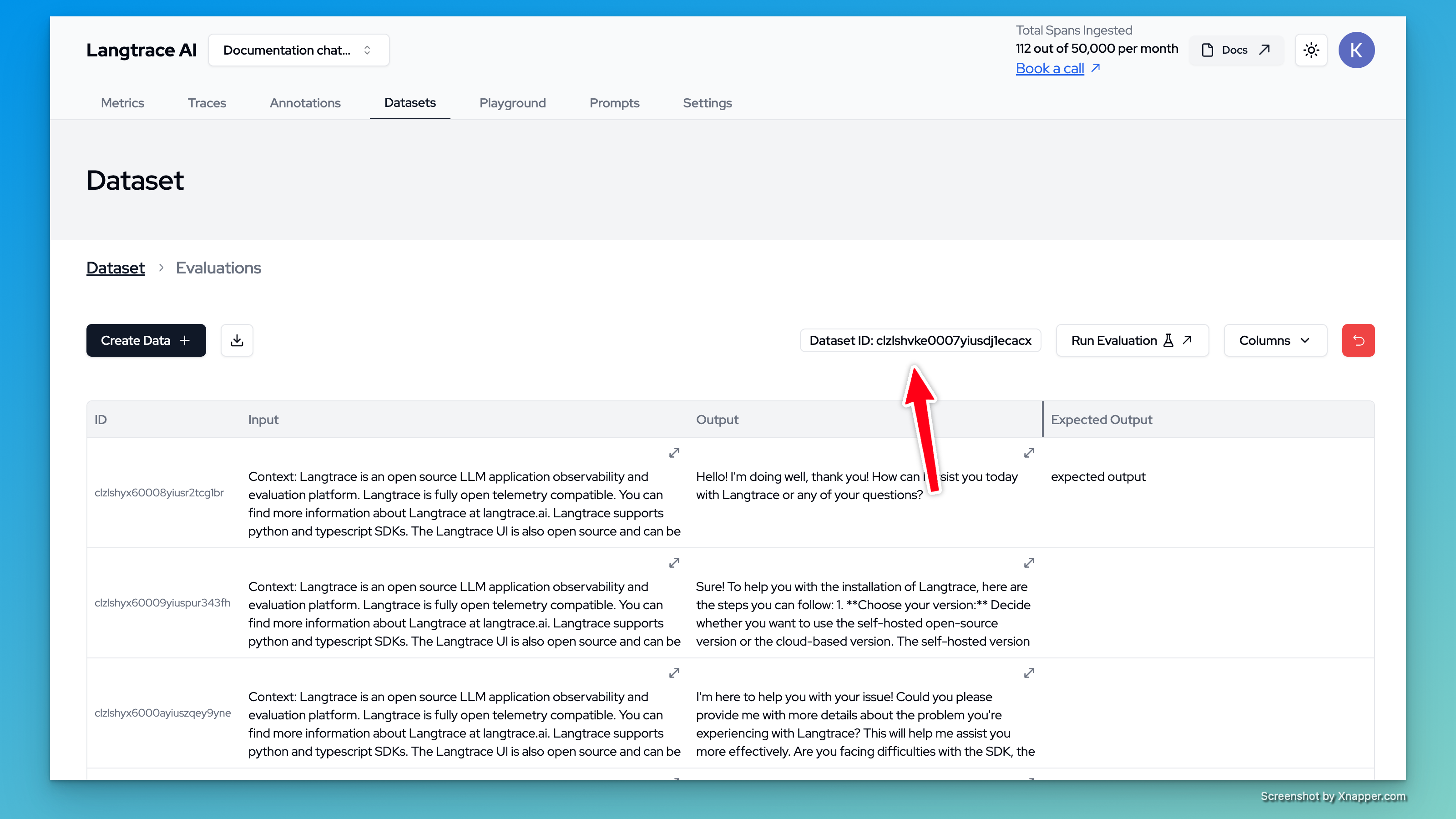
- Write a simple evaluation script and save it in a file called
example_eval.py
plan which includes a generate() step which will run each sample in the dataset against the specified model and a self_critique() step which will evaluate the performance of the model using the model_graded_fact() scorer.
The self_critique() step will compare the model’s output with the ground truth and assign a score to the model based on how well it performed and it uses gpt-4o as the model to judge the performance of the model.
- Run the evaluation script
INSPECT_LOG_FORMAT=json environment variable before running the inspect command to ensure outputs are generated in JSON format and properly uploaded to Langtrace for reporting.
- Once the evaluations are complete, you can view the results in the Langtrace dashboard by going to the evaluations page inside the dataset you ran the evaluations on.
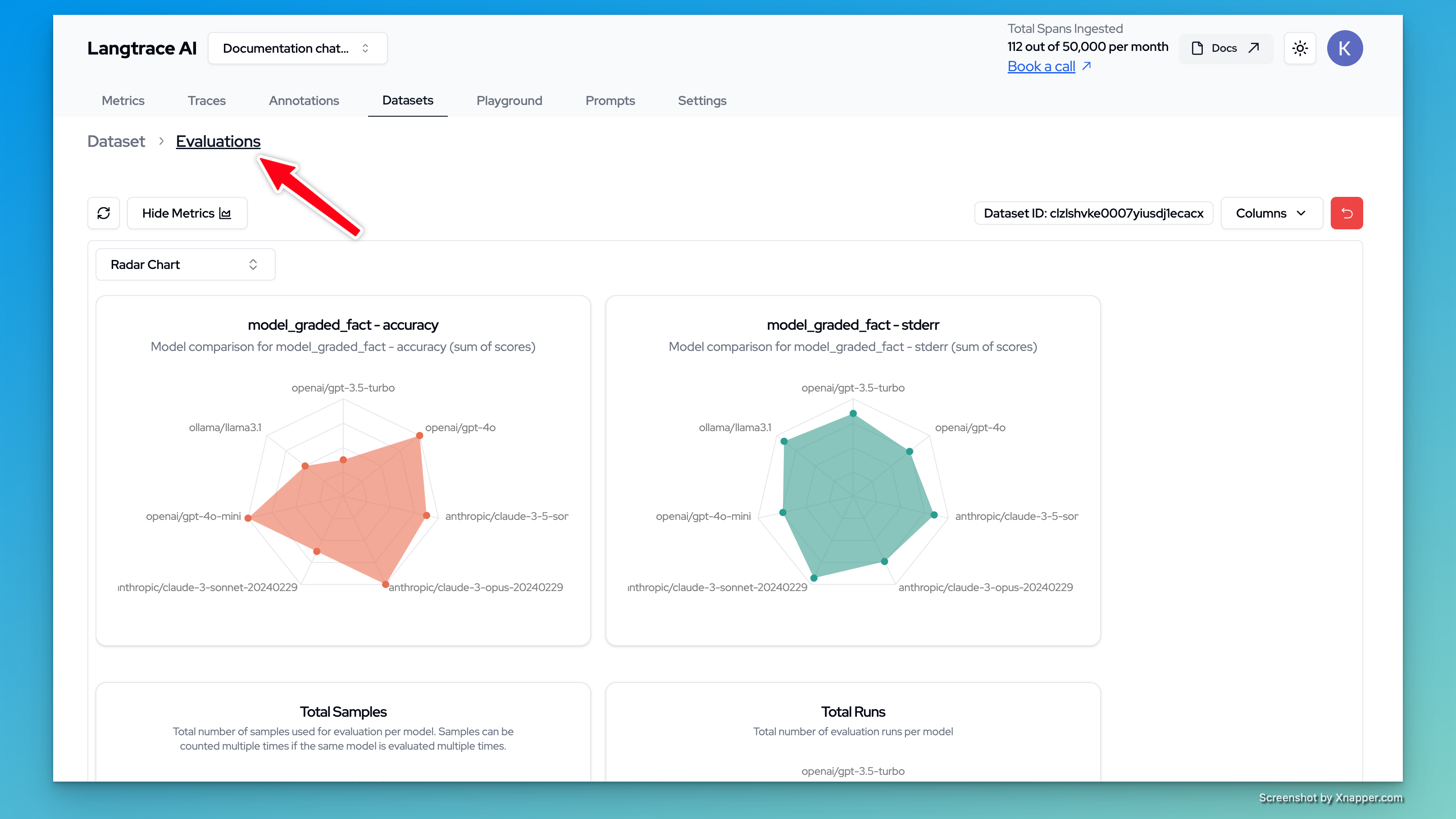
- Additionally, you can also configure the
--log-diras an environment variable as shown below: