Prerequisites
Before you begin, ensure you have the following:- An active account on the Graphlit Platform with access to the API Settings page.
- An API key from Langtrace. Sign up for Langtrace if you haven’t done so already.
Setup
- Install the Graphlit client and Langtrace’s SDK and initialize the SDK in your code.
Python
- Setup environment variables:
Shell
Usage
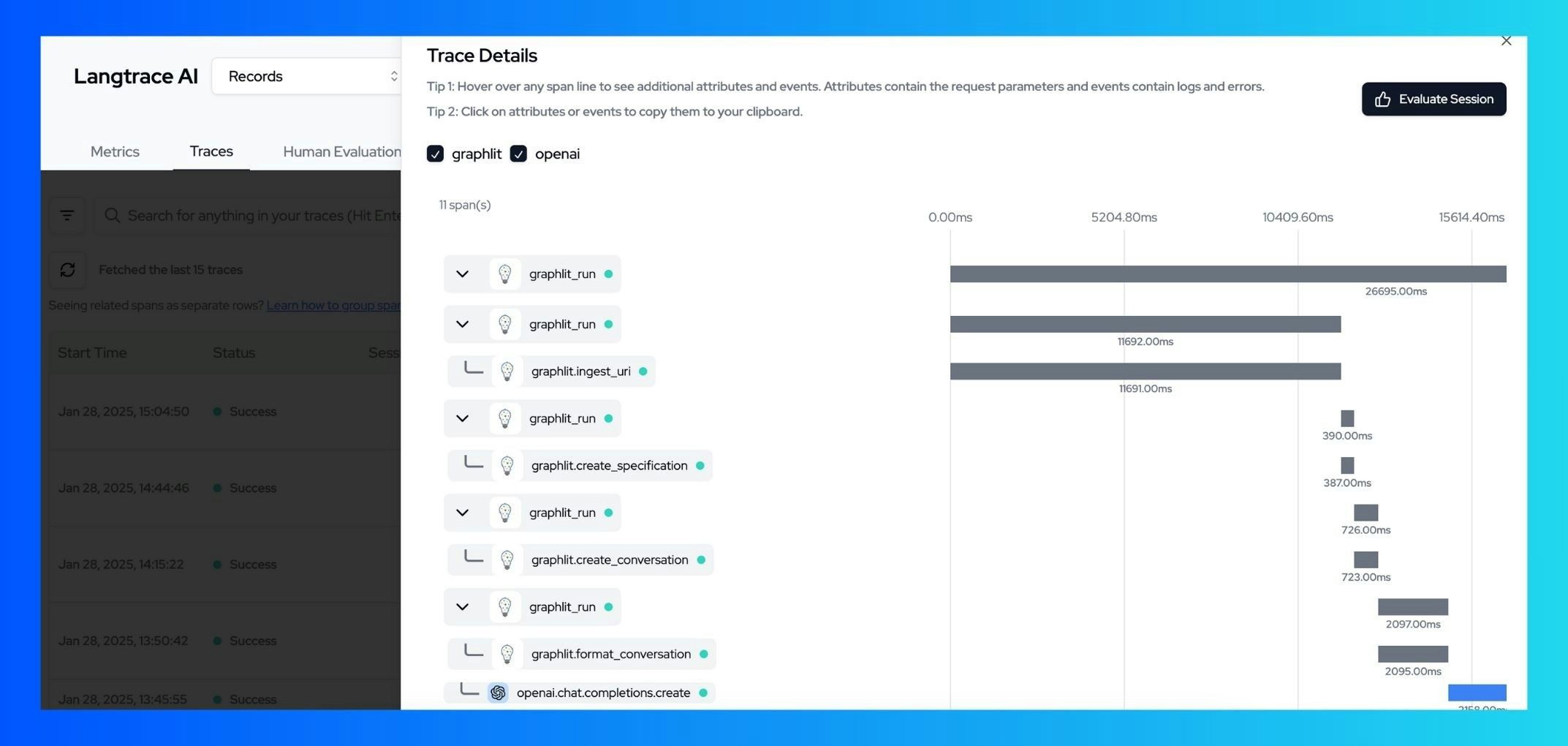
Initialize Langtrace and Graphlit:- Data ingestion metrics
- Specification creation details
- Conversation flow and completion times
- Error tracking and diagnostics