Setup
- Install the Langtrace’s SDK and initialize the SDK in your code.
- Install the Neo4j driver and the Neo4j GraphRAG library.
- Setup environment variables:
Usage
Initialize Langtrace before creating your Phidata agent:Python
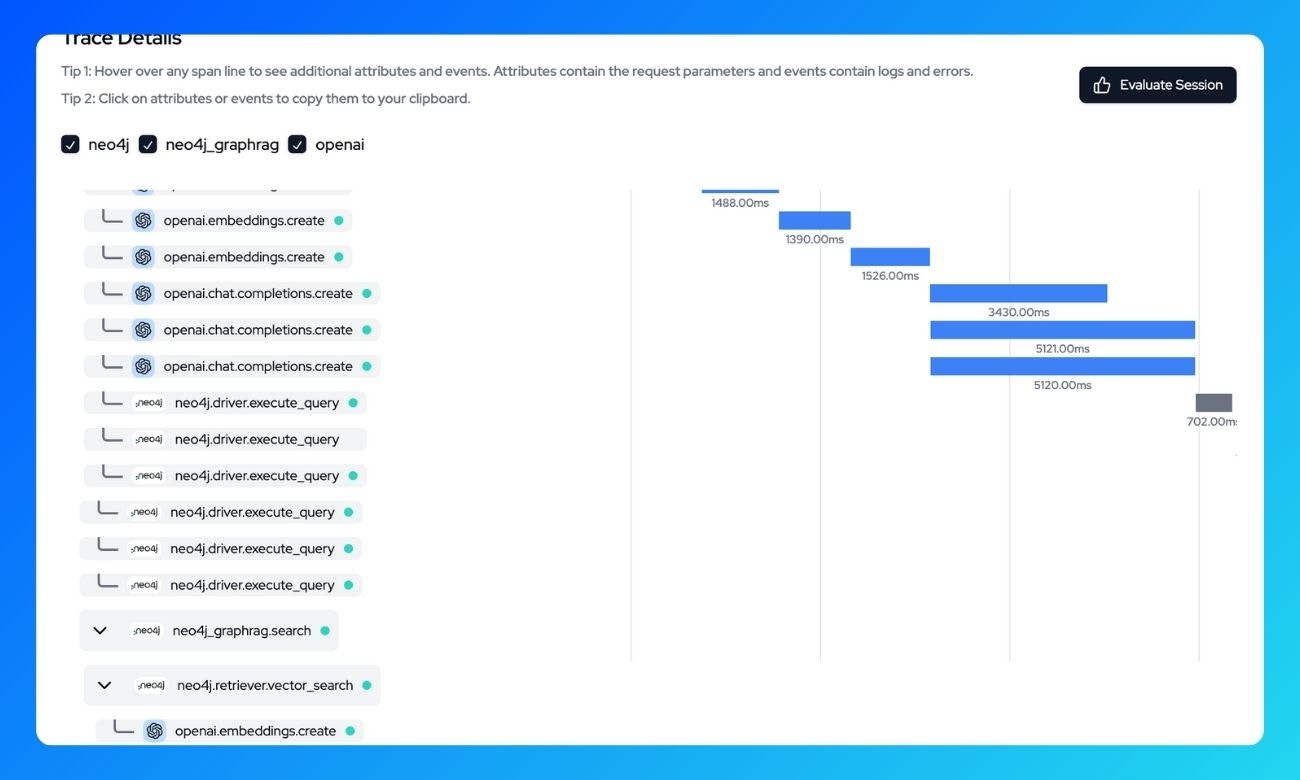
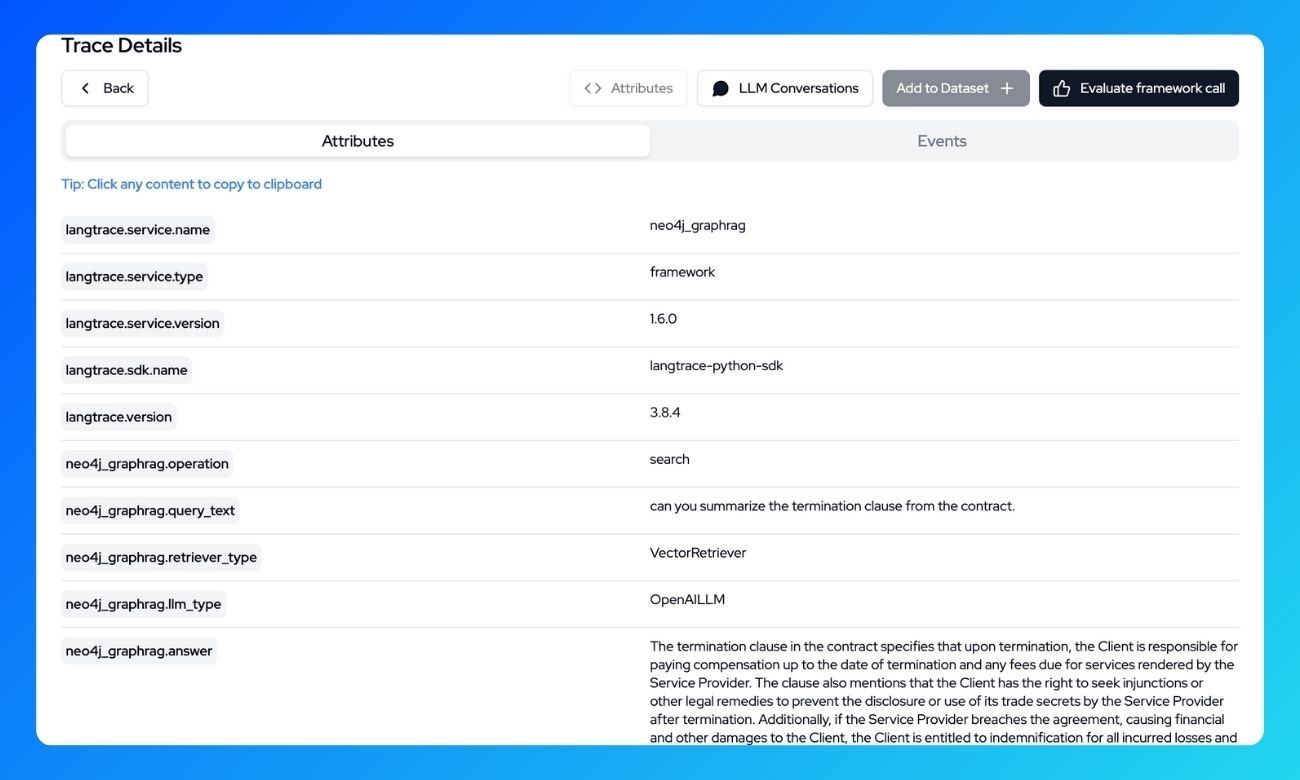
What’s being traced?
With Langtrace, the following operations are automatically traced: Knowledge Graph Building: -Document ingestion and processing -Entity extraction and relationship creation -Vector embedding generation Search and Retrieval:- Vector similarity search operations
- Subgraph extraction for context
- Retrieved document chunks
- Prompt construction with retrieved context
- Model completion generation
- Response processing